The AWS outage on 20th October 2025, dealt a serious blow to global services. It caused widespread disruption for millions of users over several hours. This single incident sharply exposed severe vulnerabilities within our modern digital infrastructure. Major international companies instantly recorded significant revenue losses. Essential government services unexpectedly went offline across the UK. Customers faced extensive frustration and service failure.
The core outage started around 8 AM BST. It ultimately impacted over 30 services across multiple regions worldwide. Crucially, the disruption reached far beyond Amazon’s own platforms. UK banks, major airlines, and vital government portals all experienced significant, cascading downtime.
In this blog post, AJ Thompson, Chief Commercial Officer at Northdoor, advises clients on securing their operations. He addresses the most common and critical questions surrounding this failure. This event forces every executive to face an uncomfortable truth:
“The harsh reality is that the cloud is just someone else’s computer, and that computer can fail.”
This warning highlights the immediate challenge.
The single biggest lesson from the AWS outage is this: The cloud is just someone else's computer, and your business continuity cannot depend entirely on someone else's infrastructure. Share on X

Understanding the true vulnerability: technical failures and systemic risk
The outage is tied to a failure in the DynamoDB service. This database hiccup occurred in Amazon’s US-EAST-1 region. This problem quickly caused a ripple effect across 14 other AWS services. It highlighted how rapidly a core cloud component problem can spread. US-EAST-1 plays a crucial part in AWS’s global setup. A failure there impacts the entire system structure. Current evidence suggests a technical glitch, not a planned cyber attack. Amazon confirmed the issue was related to DNS resolution of the DynamoDB endpoint.
The failure’s cascade effect
DynamoDB experienced critical failures at 8 AM BST. This database service supports numerous other AWS offerings. The DynamoDB failure triggered an immediate domino effect. It affected all dependent systems. The US-EAST-1 region is Amazon’s oldest and most utilised data centre. A failure here creates global ripple effects within minutes.
The hidden risks: why non-AWS companies went down
Question: When the AWS outage hit, we saw companies that don’t even use AWS directly go down. What happened there? What does that tell you about where the real risks hide?
Answer: Many organisations rely indirectly on AWS. This occurs through partners, third-party services, or SaaS applications. These applications are built on core AWS infrastructure. When AWS’s US-EAST-1 region went down, those dependencies cascaded across the ecosystem. This caused outages even for companies without direct AWS accounts.
This event exposes a critical blind spot in risk assessments. Companies often underestimate the depth of their supply chain. They fail to map cloud provider dependencies fully. The real risks live in these hidden interconnections. One failure can ripple unpredictably across industries and geographies. The disruption of UK banking platforms and HMRC services illustrates this risk perfectly.
Operational blind spots: what surprised sophisticated IT leaders
Question: What did this AWS outage reveal that surprised even sophisticated IT leaders? What are many CIOs and enterprises missing in their risk assessments and contingency planning?
Answer: This outage showed that even highly sophisticated IT organisations are often underprepared for widespread cloud provider failures. Many CIOs focus contingency plans on classic disasters. These include hardware failure, cyber attacks, or data centre loss. They often overlook the systemic vulnerability of single-region reliance. Untested failover strategies are another critical gap.
This event surprisingly exposed that assumptions about cloud resilience need updating. Critical blind spots include a lack of true multi-region or hybrid-cloud architectures. There is also limited crisis communication readiness with customers and partners.
The ‘Left of Boom’ Versus ‘Right of Boom’ Gap
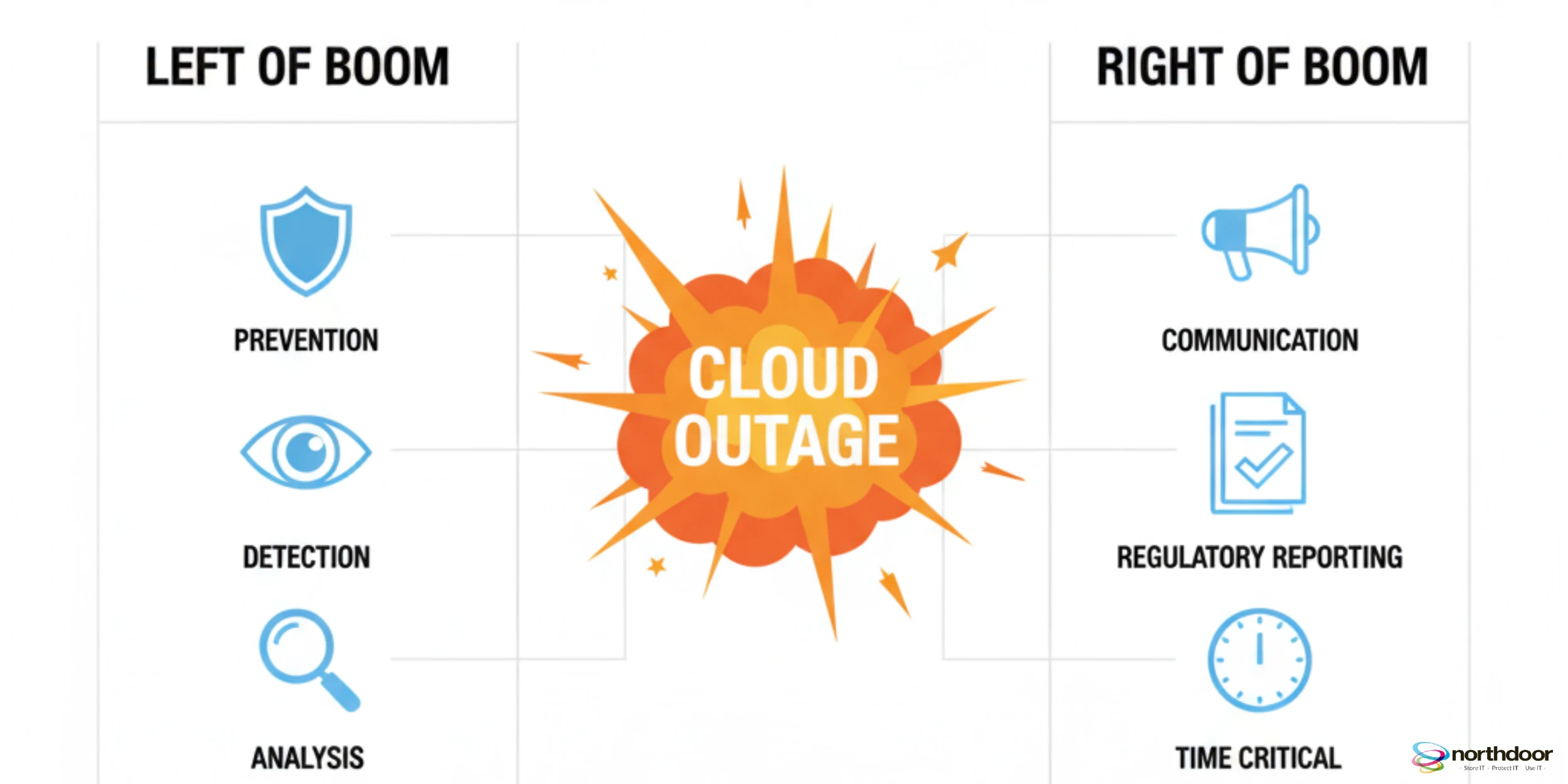
This outage exposed the dangerous gap between ‘Left of Boom’ and ‘Right of Boom’ preparedness. Organisations spend fortunes on SOCs and threat detection. These are ‘Left of Boom’ activities, designed to prevent incidents. But when the Boom happens, most teams are unprepared for the ‘Right of Boom’ reality. They lack tested communication protocols. Regulatory reporting mechanisms are often missing. Under frameworks like NIS2 and DORA, firms must notify regulators (FCA, Bank of England) within hours.
The fix requires regular tabletop exercises. These must simulate not just technical recovery. They must also cover the full spectrum of post-incident obligations.
Boardroom actions: strengthening cloud resilience posture
Question: If you were advising a board or executive team the day after this AWS outage, what are the top three actions they should take? How should they elevate this conversation beyond IT?
Answer: These are the top three actions:
- Conduct full dependency mapping: Boards must mandate a thorough mapping. Understand all cloud and third-party service interconnections. This transparency is essential for identifying hidden single points of failure.
- Implement multi-region strategy: Mandate implementation of multi-region or hybrid-cloud strategies. This reduces reliance on any single service or location. Complement this with regular, aggressive failover testing.
- Elevate resilience governance: Broadening resilience conversations beyond IT is crucial. Business continuity, finance, legal, and customer relations must all engage actively. Elevating these discussions ensures resilience becomes a shared enterprise governance priority.
AJ Thompson notes: “Board conversations must shift from reactive damage control to proactive governance of third-party dependencies. Under DORA regulations, cloud dependency is explicitly a board-level governance issue.”
Cultural shift: building organisational resilience
Question: Beyond technology, what cultural or organisational shifts most improve recovery from third-party cloud failures?
Answer: The most critical shift is moving from a technology-centric incident response culture. Organisations must adopt a business-centric resilience culture.
Recovery demands a coordinated response across the entire business. This includes legal, compliance, communications, and executive leadership. Teams must break down silos. They need to create cross-functional incident response teams. These teams must understand both technical recovery and business obligations.
Organisations need to embed ‘Right of Boom’ thinking into their culture. This means preparing for the complex stakeholder management. It means preparing for regulatory reporting decisions that follow any significant disruption. The companies that recovered fastest from this AWS outage had the most practiced, coordinated organisational response capabilities. Technology provides the tools. Culture and process determine the speed of your recovery.
Protect your operations to maintain customer trust
The October 2025 AWS outage serves as a vital lesson. Effective business continuity planning requires ongoing investment and attention. Regular testing, staff training, and system updates ensure readiness.
Ready to strengthen your business continuity plan? Contact Northdoor’s cyber security experts today. Our team helps UK businesses build resilient infrastructure. We help safeguard your operations against future cloud outages.
Call us now for a comprehensive business continuity assessment and discover how to protect your operations.
Contact Northdoor for a Resilience Assessment
Read the following related articles from our experts
- 20th November, Financial Planning, Big tech outages don’t have to shut down business for prepared advisors
- 22nd October, TechTarget, AWS cloud outage reveals vendor concentration risk
Blog: How the Cloudflare outage exposed hidden risks: expert answers to common questions